Multi-resolution deconvolution of spatial transcriptomics#
In this tutorial, we through the steps of applying DestVI for deconvolution of 10x Visium spatial transcriptomics profiles using an accompanying single-cell RNA sequencing data.
Background:
Spatial transcriptomics technologies are currently limited, because their resolution is limited to niches (spots) of sizes well beyond that of a single cell. Although several pipelines proposed joint analysis with single-cell RNA-sequencing (scRNA-seq) to alleviate this problem they are limited to a discrete view of cell type proportion inside every spot. This limitation becomes critical in the common case where, even within a cell type, there is a continuum of cell states. We present Deconvolution of Spatial Transcriptomics profiles using Variational Inference (DestVI), a probabilistic method for multi-resolution analysis for spatial transcriptomics that explicitly models continuous variation within cell types.
Plan for this tutorial:
Loading the data
Training the single-cell model (scLVM) to learn a basis of gene expression on the scRNA-seq data
Training the spatial model (stLVM) to perform the deconvolution
Visualize the learned cell type proportions
Run our automated pipeline
Dig into the intra cell type information
Run cell-type specific differential expression
Note
Running the following cell will install tutorial dependencies on Google Colab only. It will have no effect on environments other than Google Colab.
!pip install --quiet spatialvi-tools
!pip install --quiet git+https://github.com/yoseflab/destvi_utils.git@main
import tempfile
import destvi_utils
import matplotlib.pyplot as plt
import numpy as np
import scanpy as sc
import seaborn as sns
import torch
from scvi.model import CondSCVI
from spatialvi.model._destvi import DestVI
import spatialvi
spatialvi.settings.seed = 0
print("Last run with spatialvi-tools version:", spatialvi.__version__)
Seed set to 0
Last run with spatialvi-tools version: 0.1.0
Note
You can modify save_dir below to change where the data files for this tutorial are saved.
sc.set_figure_params(figsize=(6, 6), frameon=False)
sns.set_theme()
torch.set_float32_matmul_precision("high")
save_dir = tempfile.TemporaryDirectory()
%config InlineBackend.print_figure_kwargs={"facecolor": "w"}
%config InlineBackend.figure_format="retina"
Let’s download our data from a comparative study of murine lymph nodes, comparing wild-type with a stimulation after injection of a mycobacteria. We have at disposal a 10x Visium dataset as well as a matching scRNA-seq dataset from the same tissue.
url1 = "https://github.com/romain-lopez/DestVI-reproducibility/blob/master/lymph_node/deconvolution/ST-LN-compressed.h5ad?raw=true"
url2 = "https://github.com/romain-lopez/DestVI-reproducibility/blob/master/lymph_node/deconvolution/scRNA-LN-compressed.h5ad?raw=true"
out1 = "data/ST-LN-compressed.h5ad"
out2 = "data/scRNA-LN-compressed.h5ad"
Data loading & processing#
First, let’s load the single-cell data. We profiled immune cells from murine lymph nodes with 10x Chromium, as a control / case study to study the immune response to exposure to a mycobacteria (refer to our paper for more info). We provide the preprocessed data from our reproducibility repository: it contains the raw counts (DestVI always takes raw counts as input).
sc_adata = sc.read(out2, backup_url=url2)
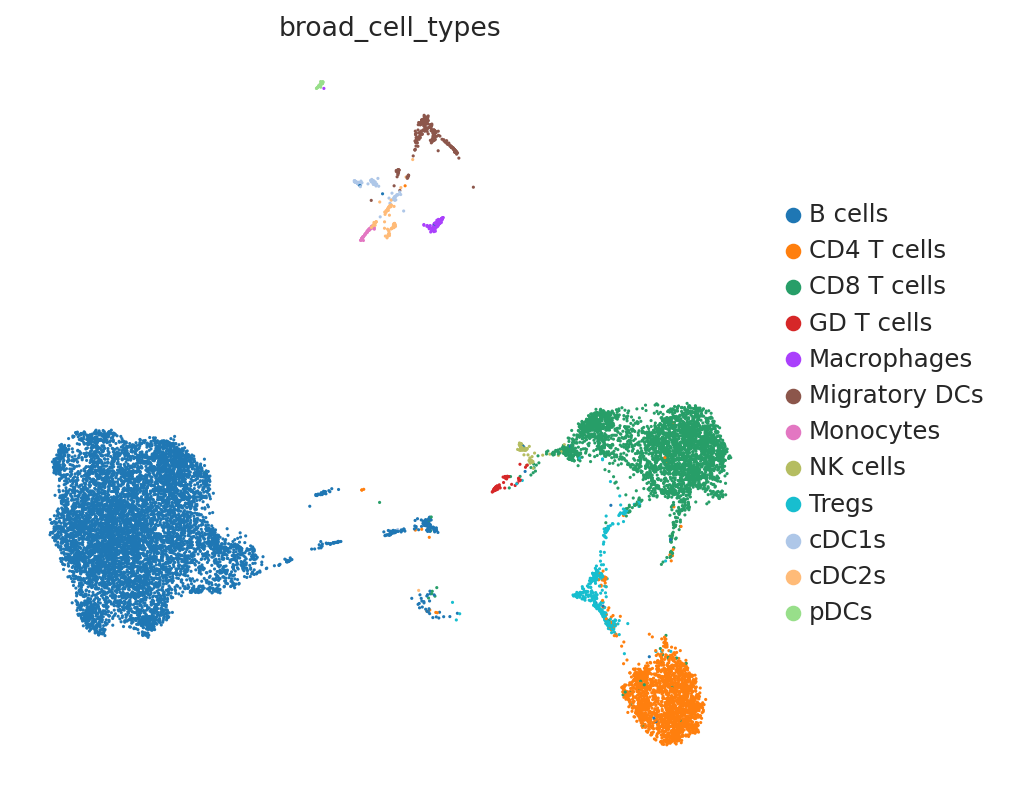
We clustered the single-cell data by major immune cell types. DestVI can resolve beyond discrete clusters, but need to work with an existing level of clustering. A rule of thumb to keep in mind while clsutering is that DestVI assumes only a single state from each cell type exists in each spot. For example, resting and inflammed monocytes cannot co-exist in one unique spot according to our assumption. Users may cluster their data so that this modeling assumption is as accurate as possible.
sc.pl.umap(sc_adata, color="broad_cell_types")
# let us filter some genes
G = 2000
sc.pp.filter_genes(sc_adata, min_counts=10)
sc_adata.layers["counts"] = sc_adata.X.copy()
sc.pp.highly_variable_genes(
sc_adata, n_top_genes=G, subset=True, layer="counts", flavor="seurat_v3"
)
sc.pp.normalize_total(sc_adata, target_sum=10e4)
sc.pp.log1p(sc_adata)
sc_adata.raw = sc_adata
Now, let’s load the spatial data and choose a common gene subset. Users will note that having a common gene set is a prerequisite of the method.
st_adata = sc.read(out1, backup_url=url1)
st_adata.layers["counts"] = st_adata.X.copy()
st_adata.obsm["spatial"] = st_adata.obsm["location"]
sc.pp.normalize_total(st_adata, target_sum=10e4)
sc.pp.log1p(st_adata)
st_adata.raw = st_adata
# filter genes to be the same on the spatial data
intersect = np.intersect1d(sc_adata.var_names, st_adata.var_names)
st_adata = st_adata[:, intersect].copy()
sc_adata = sc_adata[:, intersect].copy()
G = len(intersect)
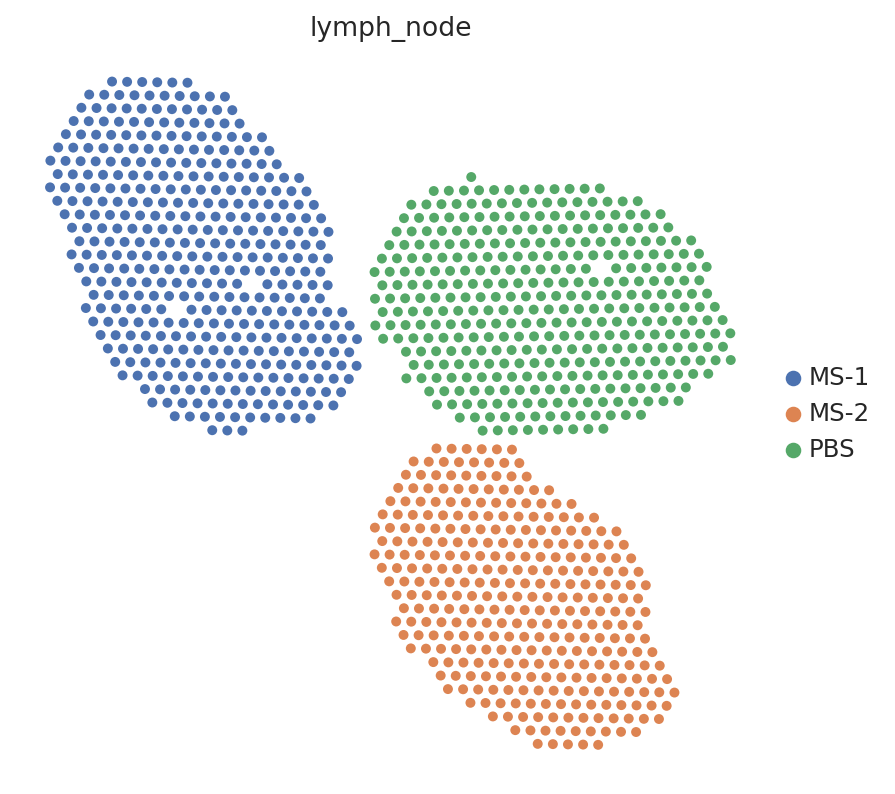
sc.pl.embedding(st_adata, basis="spatial", color="lymph_node", s=80)
Fit the scLVM#
In order to learn cell state specific gene expression patterns, we will fit the single-cell Latent Variable Model (scLVM) to single-cell RNA sequencing data from the same tissue.
sc_adata.obs.head()
| n_genes | cell_types | batch | n_genes_by_counts | total_counts | total_counts_mt | pct_counts_mt | pred_cell_types | doublet_scores | doublet_predictions | ... | louvain_sub_0.1 | louvain_sub_0.2 | louvain_sub_0.3 | louvain_sub | louvain_sub_1 | louvain_sub_2 | louvain_sub_3 | SCANVI_pred_cell_types | SCVI_pred_cell_types | broad_cell_types | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AAACCCAAGCAGAAAG-1-0 | 1505 | Tregs | 0 | 1505 | 5862.0 | 307.0 | 5.237121 | Tregs | 0.090909 | 0.0 | ... | 6 | 6 | 6 | Tregs | Tregs | 6,1 | 6,1 | Tregs | Tregs | Tregs |
| AAACCCAAGGTCACAG-1-0 | 1883 | Mature B cells | 0 | 1883 | 6673.0 | 346.0 | 5.185074 | Mature B | 0.116751 | 0.0 | ... | 0 | 0 | 0 | B cells,0 | B cells,0 | 0 | 0 | Cycling B/T cells | Mature B | B cells |
| AAACCCACATCGTTCC-1-0 | 2080 | CD8 T cells | 0 | 2080 | 7764.0 | 438.0 | 5.641422 | CD122+ CD8 T | 0.041626 | 0.0 | ... | 1 | 1-3,0 | 1 | CD8 T cells | CD8 T cells | 1-3,0 | 1-3,0 | CD8 T | CD8 T | CD8 T cells |
| AAACCCAGTCGTCTCT-1-0 | 1647 | Cycling B/T cells | 0 | 1647 | 4619.0 | 265.0 | 5.737173 | Mature B | 0.098634 | 0.0 | ... | 5 | 5 | 5 | B cells,7 | B cells,7 | 5 | 5 | Ifit3-high B | Mature B | B cells |
| AAACCCAGTGTAAACA-1-0 | 1857 | Mature B cells | 0 | 1857 | 5965.0 | 339.0 | 5.683152 | Mature B | 0.153374 | 0.0 | ... | 0 | 0 | 0 | B cells,3 | B cells,3 | 0 | 0 | B-macrophage doublets | Mature B | B cells |
5 rows × 31 columns
CondSCVI.setup_anndata(
sc_adata,
layer="counts",
labels_key="broad_cell_types",
fine_labels_key="cell_types",
batch_key="batch",
)
As a first step, we embed our data using a cell type conditional VAE. We pass the layer containing the raw counts and the labels key. We train this model without reweighting the loss by the cell type abundance. Training will take around 5 minutes in a Colab GPU session.
sc_model = CondSCVI(sc_adata, weight_obs=False, prior="mog", num_classes_mog=10)
sc_model.view_anndata_setup()
Anndata setup with scvi-tools version 1.4.0.post1.
Setup via `CondSCVI.setup_anndata` with arguments:
{ │ 'batch_key': 'batch', │ 'labels_key': 'broad_cell_types', │ 'fine_labels_key': 'cell_types', │ 'layer': 'counts', │ 'unlabeled_category': 'unlabeled', │ 'size_factor_key': None }
Summary Statistics ┏━━━━━━━━━━━━━━━━━━┳━━━━━━━┓ ┃ Summary Stat Key ┃ Value ┃ ┡━━━━━━━━━━━━━━━━━━╇━━━━━━━┩ │ n_batch │ 4 │ │ n_cells │ 14989 │ │ n_fine_labels │ 16 │ │ n_labels │ 12 │ │ n_vars │ 1888 │ └──────────────────┴───────┘
Data Registry ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Registry Key ┃ scvi-tools Location ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ X │ adata.layers['counts'] │ │ batch │ adata.obs['_scvi_batch'] │ │ fine_labels │ adata.obs['_scvi_fine_labels'] │ │ labels │ adata.obs['_scvi_labels'] │ └──────────────┴────────────────────────────────┘
labels State Registry ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['broad_cell_types'] │ B cells │ 0 │ │ │ CD4 T cells │ 1 │ │ │ CD8 T cells │ 2 │ │ │ GD T cells │ 3 │ │ │ Macrophages │ 4 │ │ │ Migratory DCs │ 5 │ │ │ Monocytes │ 6 │ │ │ NK cells │ 7 │ │ │ Tregs │ 8 │ │ │ cDC1s │ 9 │ │ │ cDC2s │ 10 │ │ │ pDCs │ 11 │ └───────────────────────────────┴───────────────┴─────────────────────┘
batch State Registry ┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['batch'] │ 0 │ 0 │ │ │ 1 │ 1 │ │ │ 2 │ 2 │ │ │ 3 │ 3 │ └────────────────────┴────────────┴─────────────────────┘
fine_labels State Registry ┏━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['cell_types'] │ CD4 T cells │ 0 │ │ │ CD8 T cells │ 1 │ │ │ Cxcl9-high monocytes │ 2 │ │ │ Cycling B/T cells │ 3 │ │ │ GD T cells │ 4 │ │ │ Ifit3-high B cells │ 5 │ │ │ Ly6-high monocytes │ 6 │ │ │ Macrophages │ 7 │ │ │ Mature B cells │ 8 │ │ │ Migratory DCs │ 9 │ │ │ NK cells │ 10 │ │ │ Tregs │ 11 │ │ │ cDC1s │ 12 │ │ │ cDC2s │ 13 │ │ │ pDCs │ 14 │ │ │ unlabeled │ 15 │ └─────────────────────────┴──────────────────────┴─────────────────────┘
sc_model.train()
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/lightning/pytorch/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
/opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:434: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=300` reached.
sc_model.history["elbo_train"].iloc[5:].plot()
plt.show()
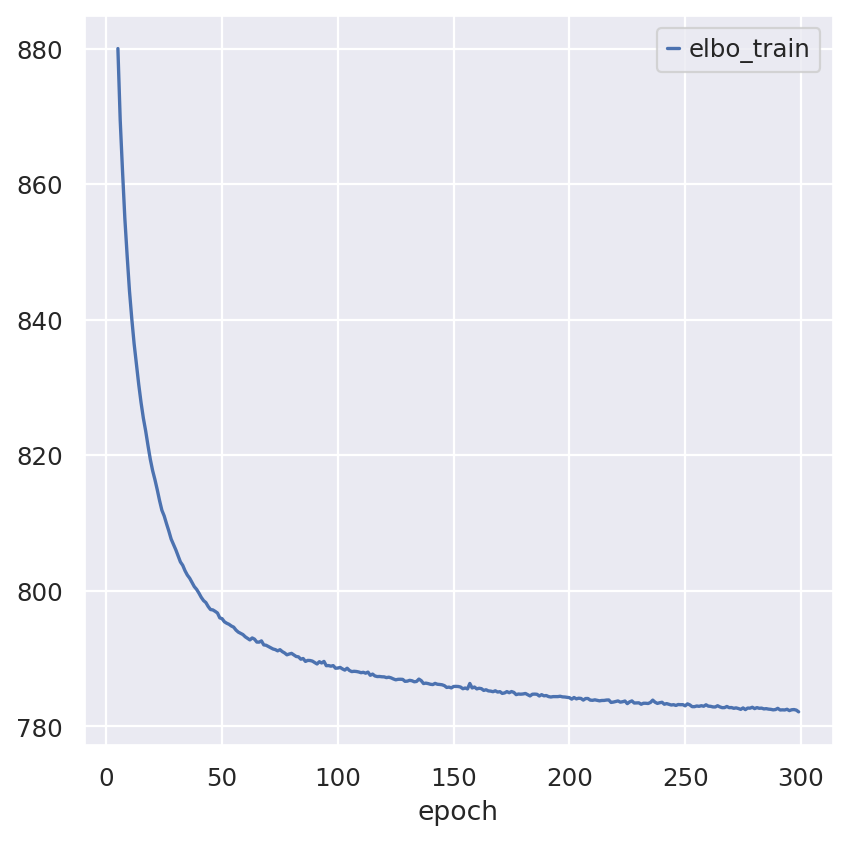
Note that model converges quickly. Over experimentation with the model drastically reducing the number of epochs leads to decreased performance and performance deteriorates as max_epochs<200.
Deconvolution with stLVM#
As a second step, we train our deconvolution model: spatial transcriptomics Latent Variable Model (stLVM).
We setup the DestVI model using the counts layer in st_adata that contains the raw counts. We then pass the trained CondSCVI model and generate a new model based on st_adata and sc_model using DestVI.from_rna_model.
# Deconvolution with stLVM
st_adata = st_adata[st_adata.layers["counts"].sum(1) > 10].copy()
st_adata.obs["batch"] = "spatial"
def spatial_nn_gex_smth(stadata, n_neighs):
sc.pp.neighbors(stadata, n_neighs, use_rep="spatial", key_added="Xspatial")
stadata.obsp["Xspatial_connectivities"] = stadata.obsp["Xspatial_connectivities"].ceil()
stadata.obsp["Xspatial_connectivities"].setdiag(1)
return stadata.obsp["Xspatial_connectivities"].dot(stadata.layers["counts"])
st_adata.layers["smoothed"] = spatial_nn_gex_smth(st_adata, n_neighs=5)
The decoder network architecture will be generated from sc_model. Two neural networks are initiated for cell type proportions and gamma value amortization. Training will take around 5 minutes in a Colab GPU session.
Potential adaptations of DestVI.from_rna_model are:
increasing
vamp_prior_pleads to less gradual changes in gamma valuesmore discretized values. Increasing
l1_sparsitywill lead to sparser results for cell type proportions.Although we recommend using similar sequencing technology for both assays, consider changing
beta_weighting_priorotherwise.
Technical Note: During inference, we adopt a variational mixture of posterior as a prior to enforce gamma values in stLVM match scLVM (see details in original publication). This empirical prior is based on cell type specific subclustering (using k-means to find vamp_prior_p clusters) of the posterior distribution in latent space for every cell.
st_model = DestVI.from_rna_model(
st_adata,
sc_model,
add_celltypes=2,
n_latent_amortization=None,
anndata_setup_kwargs={"smoothed_layer": "smoothed"},
)
st_model.view_anndata_setup()
Anndata setup with scvi-tools version 1.4.0.post1.
Setup via `DestVI.setup_anndata` with arguments:
{'layer': 'counts', 'smoothed_layer': 'smoothed', 'batch_key': 'batch'}
Summary Statistics ┏━━━━━━━━━━━━━━━━━━┳━━━━━━━┓ ┃ Summary Stat Key ┃ Value ┃ ┡━━━━━━━━━━━━━━━━━━╇━━━━━━━┩ │ n_batch │ 5 │ │ n_cells │ 1092 │ │ n_vars │ 1888 │ │ n_x_smoothed │ 1888 │ └──────────────────┴───────┘
Data Registry ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Registry Key ┃ scvi-tools Location ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ X │ adata.layers['counts'] │ │ batch │ adata.obs['_scvi_batch'] │ │ ind_x │ adata.obs['_indices'] │ │ x_smoothed │ adata.layers['smoothed'] │ └──────────────┴──────────────────────────┘
batch State Registry ┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['batch'] │ 0 │ 0 │ │ │ 1 │ 1 │ │ │ 2 │ 2 │ │ │ 3 │ 3 │ │ │ spatial │ 4 │ └────────────────────┴────────────┴─────────────────────┘
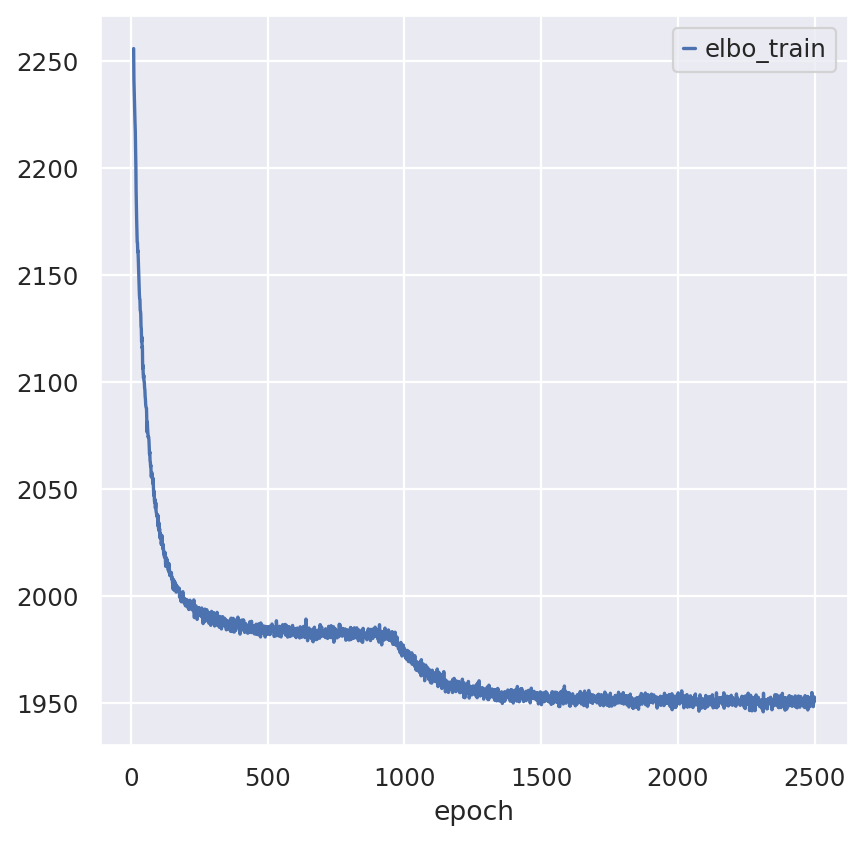
st_model.train(max_epochs=2500)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/lightning/pytorch/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
/opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:434: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
/opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/lightning/pytorch/loops/fit_loop.py:317: The number of training batches (9) is smaller than the logging interval Trainer(log_every_n_steps=10). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
`Trainer.fit` stopped: `max_epochs=2500` reached.
Note that model converges quickly. Over experimentation with the model drastically reducing the number of epochs leads to decreased performance and we advocate against max_epochs<1000.
st_model.history["elbo_train"].iloc[10:].plot()
plt.show()
The output of DestVI has two resolution. At the broader resolution, DestVI returns the cell type proportion in every spot. At the more granular resolution, DestVI can impute cell type specific gene expression in every spot.
Cell type proportions#
We extract the computed cell type proportions and display them in spatial embedding. These values are directly calculated by normalized the spot-level parameters from the stLVM model.
st_adata.obsm["proportions"] = st_model.get_proportions()
st_adata.obsm["proportions"].head(5)
| B cells | CD4 T cells | CD8 T cells | GD T cells | Macrophages | Migratory DCs | Monocytes | NK cells | Tregs | cDC1s | cDC2s | pDCs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AAACCGGGTAGGTACC-1-0 | 0.661726 | 0.005464 | 0.073862 | 0.005208 | 0.048653 | 0.025096 | 0.054515 | 0.000667 | 0.035877 | 0.064036 | 0.007584 | 0.017311 |
| AAACCTCATGAAGTTG-1-0 | 0.625187 | 0.045684 | 0.053889 | 0.019584 | 0.034942 | 0.065207 | 0.062890 | 0.000980 | 0.035806 | 0.040936 | 0.009929 | 0.004966 |
| AAAGACTGGGCGCTTT-1-0 | 0.561870 | 0.045906 | 0.087013 | 0.005674 | 0.060240 | 0.076710 | 0.017278 | 0.000701 | 0.044569 | 0.054439 | 0.032678 | 0.012920 |
| AAAGGGCAGCTTGAAT-1-0 | 0.110531 | 0.049293 | 0.321188 | 0.015721 | 0.064899 | 0.135906 | 0.055615 | 0.006855 | 0.105271 | 0.077968 | 0.051695 | 0.005058 |
| AAAGTCGACCCTCAGT-1-0 | 0.795291 | 0.034744 | 0.006223 | 0.001372 | 0.050949 | 0.021452 | 0.009435 | 0.001736 | 0.013347 | 0.044980 | 0.017892 | 0.002579 |
ct_list = ["B cells", "CD8 T cells", "Monocytes"]
for ct in ct_list:
data = st_adata.obsm["proportions"][ct].values
st_adata.obs[ct] = np.clip(data, 0, np.quantile(data, 0.99))
sc.pl.embedding(st_adata, basis="spatial", color=ct_list, cmap="Reds", s=80)
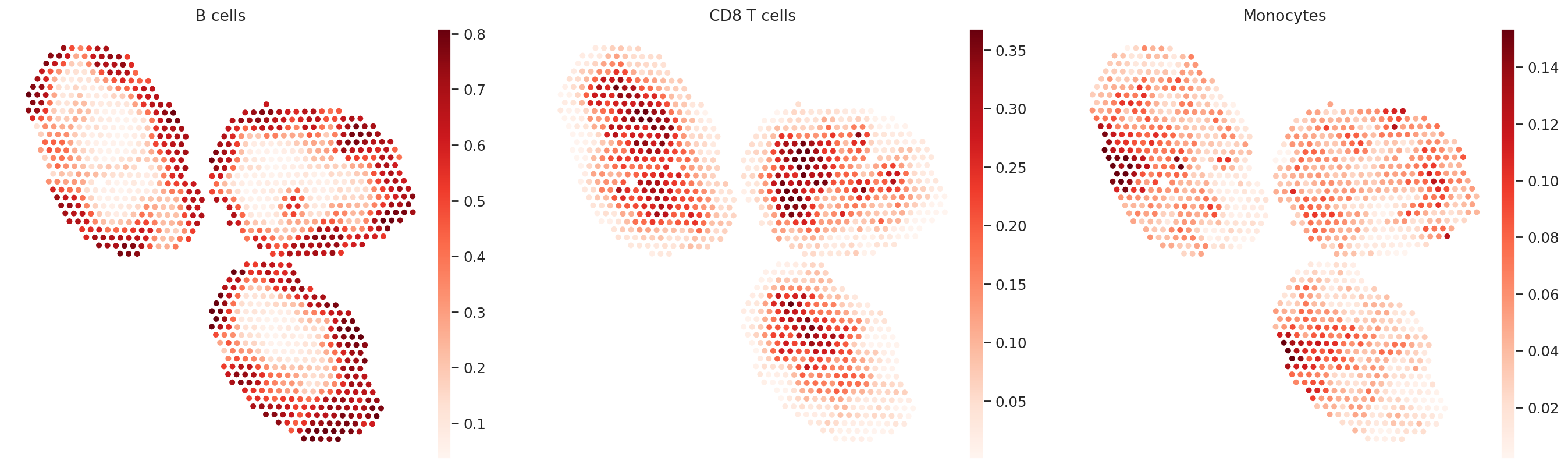
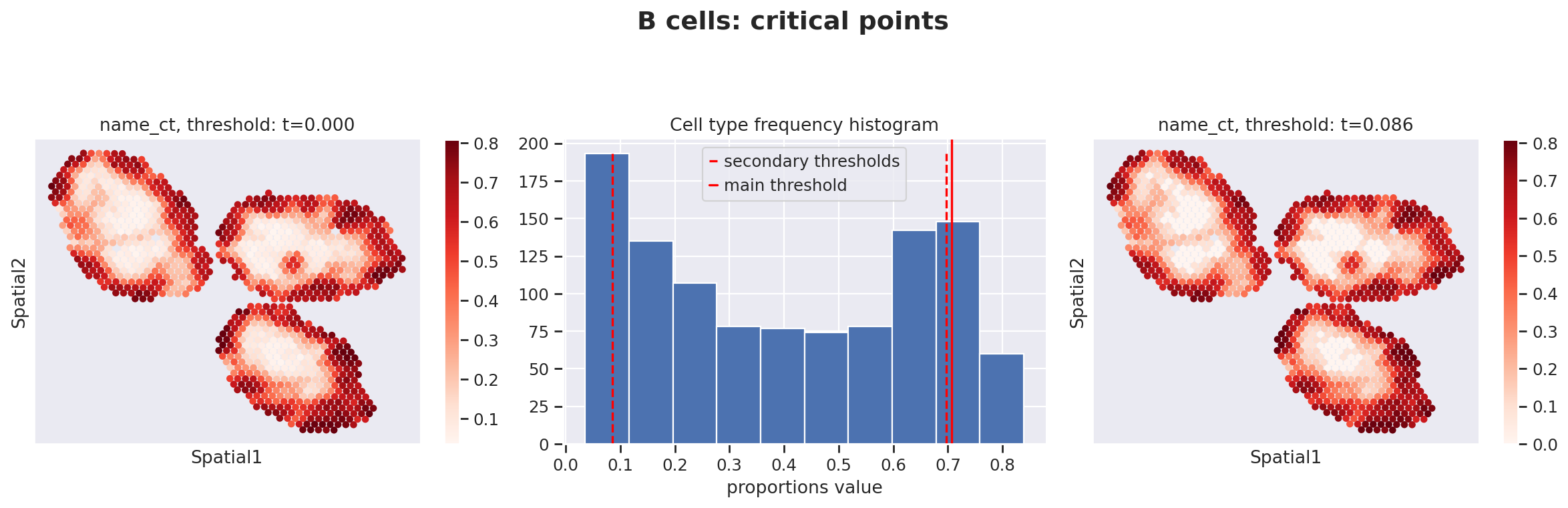
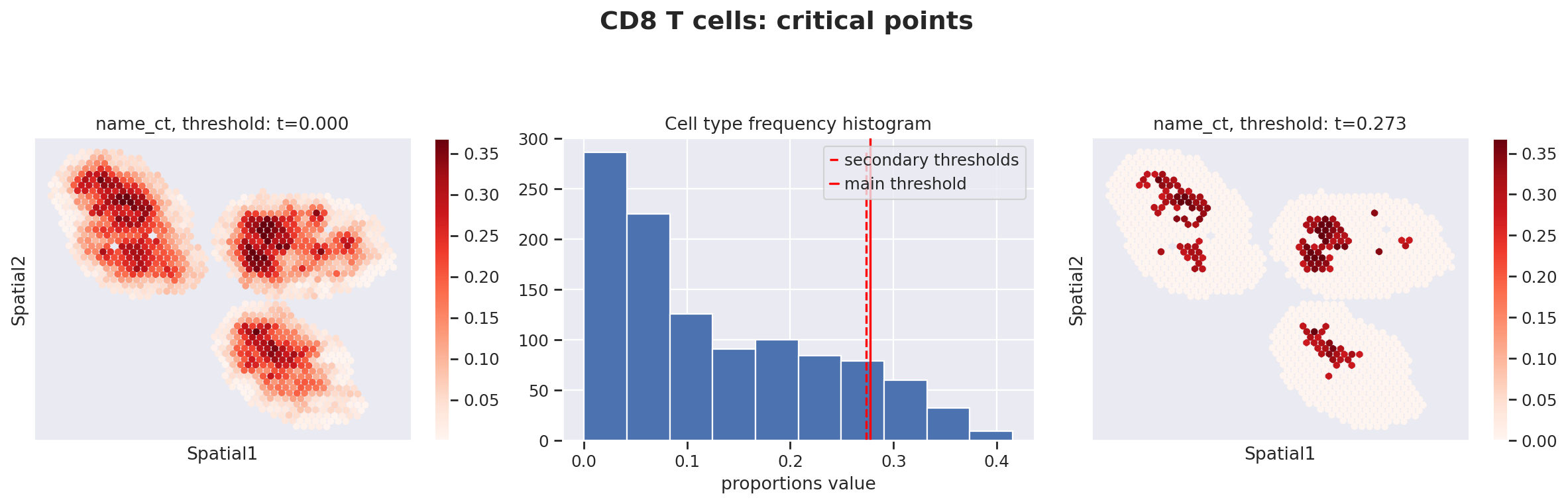
Because the inference of cell type specific gene expression is prone to error when the cell type is not present in a spot, and because the cell type proportion values estimated by stLVM are not sparse, we provide an automated way of thresholding them. For follow-up analysis we recommend checking these threshold values and adjust them for each cell type.
This part of the software is not directly available in scvi-tools, but instead in the util package destvi_utils (installable from GitHub; refer to the top of this tutorial).
ct_thresholds = destvi_utils.automatic_proportion_threshold(
st_adata, ct_list=ct_list, kind_threshold="secondary"
)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:00<00:00, 466.26it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:00<00:00, 49200.05it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:00<00:00, 44998.43it/s]
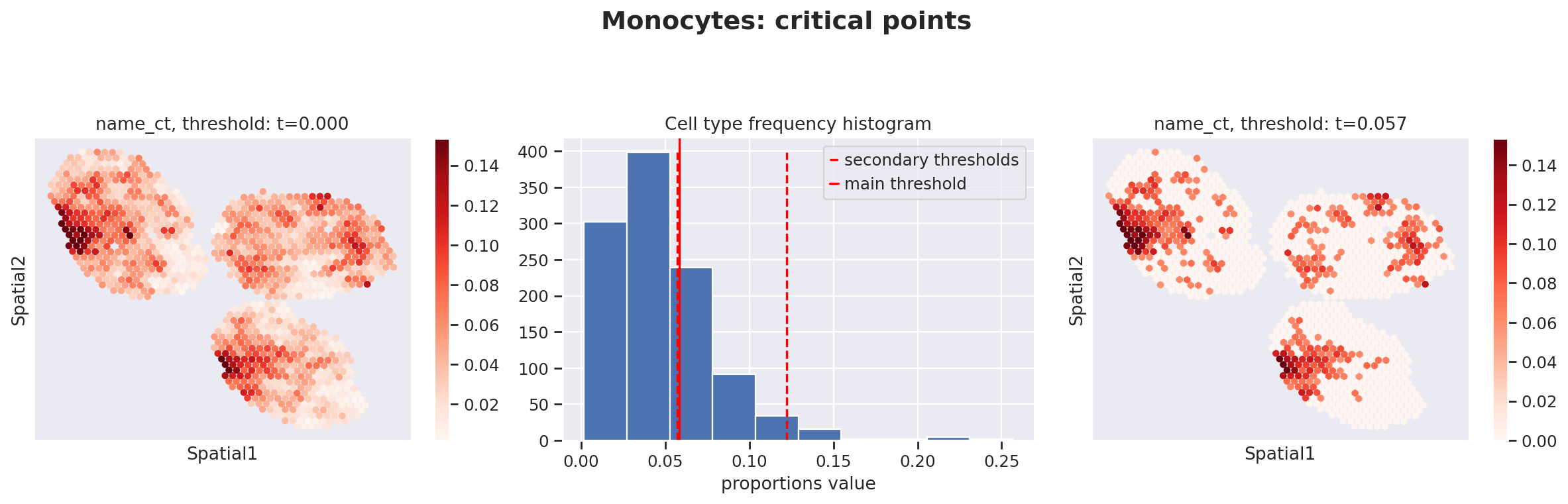
In terms of cell type location, we observe a strong compartimentalization of the cell types in the lymph node (B cells / T cells), as expected. We also observe a differential localization of the monocytes (refer to the paper for further details).
Intra cell type information#
At the heart of DestVI is a multitude of latent variables (5 per cell type per spots). We refer to them as “gamma”, and we may manually examine them for downstream analysis
# more globally, the values of the gamma are all summarized in this dictionary of data frames
for ct, g in st_model.get_gamma().items():
st_adata.obsm[f"{ct}_gamma"] = g
st_adata.obsm["B cells_gamma"].head(5)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| AAACCGGGTAGGTACC-1-0 | -0.469124 | 0.712543 | 0.511393 | -0.874085 | 2.057635 |
| AAACCTCATGAAGTTG-1-0 | -0.353509 | -0.061891 | 0.526819 | -1.245258 | 1.940330 |
| AAAGACTGGGCGCTTT-1-0 | 0.998892 | 0.124152 | 0.546279 | -0.700124 | 0.021571 |
| AAAGGGCAGCTTGAAT-1-0 | 0.000077 | -0.064286 | 0.808964 | -0.792126 | 0.208186 |
| AAAGTCGACCCTCAGT-1-0 | -0.216527 | -0.408928 | 0.267746 | -1.107363 | 1.951317 |
Because those values may be hard to examine manually for end-users, we presented in the manuscript several methods for prioritizing the study of different cell types (based on spatially-weighted PCA and Hotspot). Below we provide the result of our automated pipeline with the spatially-weighted PCA.
More precisely, for de novo detection of spatial patterns, we study the gamma space and use a spatially-informed PCA to find the spatial axis of variation in this gamma space. We use EnrichR to functionally annotate these genes. In particular, we recover enrichment of IFN genes across monocytes as well as B cells
The function explore_gamma_space operates as follow, for each cell type individually:
Select all the spots with proportions beyond the magnitude threshold,
Calculate the spot-specific cell-type-specific embeddings gamma,
Calculate the first two principal vectors of those gamma values, weighted by the spatial coordinates,
Project all the embeddings (considered spots, and single-cell profiles) onto this 2D space,
Map each spot (or cell) to a specific color via its 2d coordinate, using the
cmap2dpackagePlot (A) the color of every spot in spatial coordinates (B) the color of every spot in sPC space (C) the color of every single cell in sPC space
Calculate genes enriched in each direction and group into pathways with
EnrichR
destvi_utils.explore_gamma_space(st_model, sc_model, ct_list=ct_list, ct_thresholds=ct_thresholds)
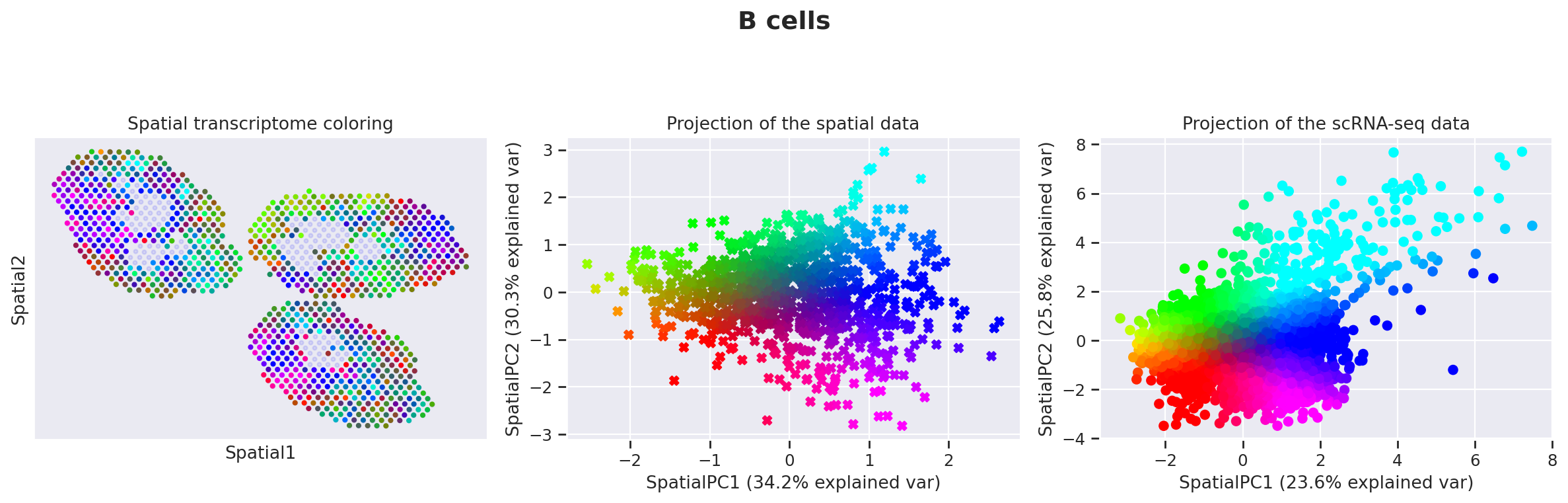
Genes associated with SpatialPC1
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[30], line 1
----> 1 destvi_utils.explore_gamma_space(st_model, sc_model, ct_list=ct_list, ct_thresholds=ct_thresholds)
File /opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/destvi_utils/_destvi_utils.py:342, in explore_gamma_space(st_model, sc_model, st_adata, ct_thresholds, output_file, ct_list, key_proportions, key_spatial)
340 ranking = ranking[::-1]
341 gl = list(st_adata.var.index[ranking[:50]])
--> 342 enr = gseapy.enrichr(
343 gene_list=gl,
344 gene_sets="BioPlanet_2019",
345 outdir="test",
346 organism="Human",
347 no_plot=True,
348 )
349 text_signatures = enr.results.head(10)["Term"].values
350 for i in range(len(text_signatures)):
File /opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/gseapy/__init__.py:567, in enrichr(gene_list, gene_sets, organism, outdir, background, cutoff, format, figsize, top_term, no_plot, verbose)
553 enr = Enrichr(
554 gene_list,
555 gene_sets,
(...) 564 verbose,
565 )
566 # set organism
--> 567 enr.set_organism()
568 enr.run()
570 return enr
File /opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/gseapy/enrichr.py:373, in Enrichr.set_organism(self)
371 if self.organism not in self.db_map:
372 valid_opts = ", ".join(sorted(set(self.db_map.keys())))
--> 373 raise ValueError(
374 f"Invalid organism '{self.organism}'. Valid options are: {valid_opts}"
375 )
376 instance = self.db_map[self.organism]
377 # Set the dynamic base URL
ValueError: Invalid organism 'Human'. Valid options are: c. elegans, caenorhabditis elegans, celegans, d. melanogaster, d. rerio, danio rerio, drosophila, drosophila melanogaster, enrichr, fish, fly, h. sapiens, homo sapiens, hs, hsapiens, human, m. musculus, mm, mouse, mus musculus, nematode, s. cerevisiae, saccharomyces, saccharomyces cerevisiae, worm, yeast, zebrafish
We anticipate this to be a valuable ressource for formulating scientific hypotheses from ST data.
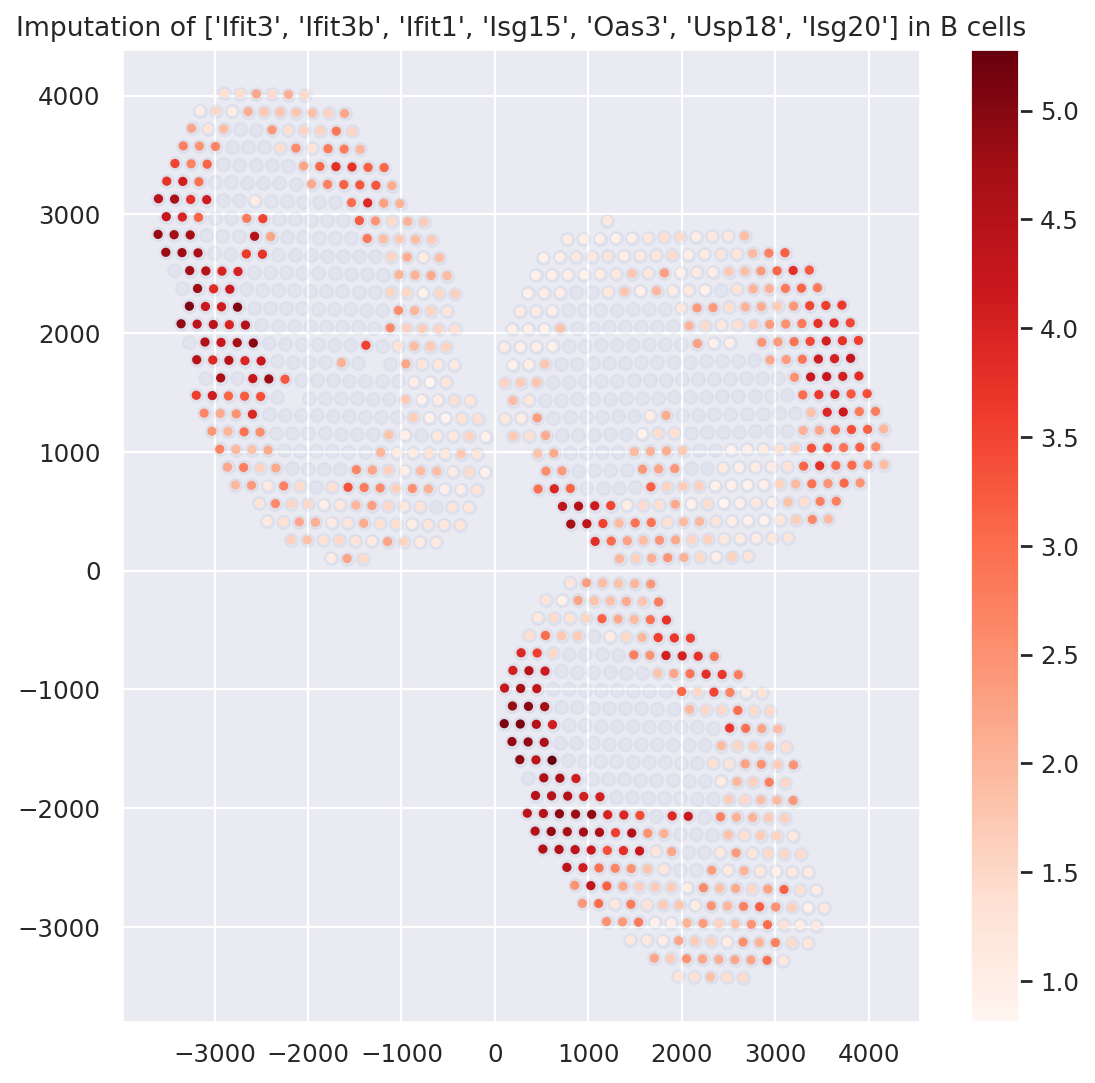
Example with B cells; and differential expression#
First, we display the genes identified via the pipeline as well as Hotspot (see manuscript), using the B-cell-specific gene expression values imputed by DestVI.
plt.figure(figsize=(8, 8))
ct_name = "B cells"
gene_name = ["Ifit3", "Ifit3b", "Ifit1", "Isg15", "Oas3", "Usp18", "Isg20"]
# we must filter spots with low abundance (consult the paper for an automatic procedure)
indices = np.where(st_adata.obsm["proportions"][ct_name].values > 0.2)[0]
# impute genes and combine them
specific_expression = np.sum(st_model.get_scale_for_ct(ct_name, indices=indices)[gene_name], 1)
specific_expression = np.log(1 + 1e4 * specific_expression)
# plot (i) background (ii) g
plt.scatter(st_adata.obsm["location"][:, 0], st_adata.obsm["location"][:, 1], alpha=0.05)
plt.scatter(
st_adata.obsm["location"][indices][:, 0],
st_adata.obsm["location"][indices][:, 1],
c=specific_expression,
s=10,
cmap="Reds",
)
plt.colorbar()
plt.title(f"Imputation of {gene_name} in {ct_name}")
plt.show()
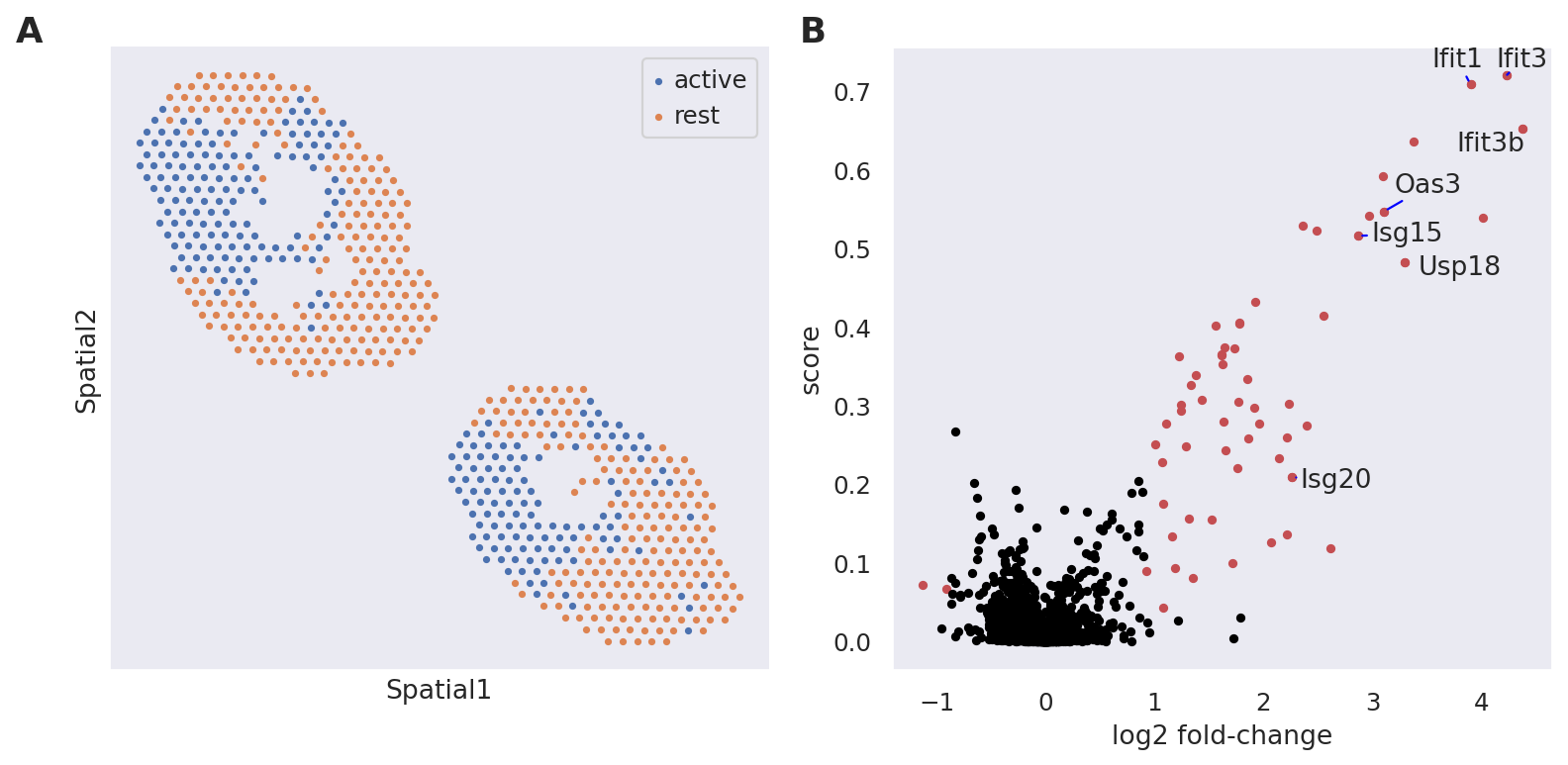
Second, we apply a Kolmogorov-Smirnov test on the generated counts to study the differential expression of B cells in the exposed lymph nodes, between the interfollicular area (IFA) and the rest. We display the identified IFN genes in a Volcano plot and see significant upregulation in the IFA area of exposed lymph nodes.
ct = "B cells"
imputation = st_model.get_scale_for_ct(ct)
color = np.log(1 + 1e5 * imputation["Ifit3"].values)
threshold = 4
mask = np.logical_and(
np.logical_or(st_adata.obs["LN"] == "TC", st_adata.obs["LN"] == "BD"),
color > threshold,
).values
mask2 = np.logical_and(
np.logical_or(st_adata.obs["LN"] == "TC", st_adata.obs["LN"] == "BD"),
color < threshold,
).values
_ = destvi_utils.de_genes(
st_model, mask=mask, mask2=mask2, threshold=ct_thresholds[ct], ct=ct, key="IFN_rich"
)
display(st_adata.uns["IFN_rich"]["de_results"].head(10))
destvi_utils.plot_de_genes(
st_adata,
interesting_genes=["Ifit3", "Ifit3b", "Ifit1", "Isg15", "Oas3", "Usp18", "Isg20"],
key="IFN_rich",
)
/opt/anaconda3/envs/scvi_new/lib/python3.13/site-packages/destvi_utils/_destvi_utils.py:467: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
torch.distributions.Gamma(concentration=concentration[mask_], rate=rate)
| log2FC | score | pval | |
|---|---|---|---|
| Ifit3 | 4.232114 | 0.720877 | 0.0 |
| Ifit1 | 3.897517 | 0.708491 | 0.0 |
| Ifit3b | 4.374247 | 0.653066 | 0.0 |
| Ifit2 | 3.371728 | 0.635789 | 0.0 |
| Slfn5 | 3.089741 | 0.592031 | 0.0 |
| Oas3 | 3.101722 | 0.547030 | 0.0 |
| Ifitm3 | 2.965460 | 0.542119 | 0.0 |
| Rsad2 | 4.010224 | 0.539512 | 0.0 |
| Cmpk2 | 2.355831 | 0.528840 | 0.0 |
| Irf7 | 2.484961 | 0.523264 | 0.0 |